|
Hi, I am a research scientist with Scale's Safety, Evaluations, and Alignment Lab (SEAL). I am currently working on evaluations and human oversight of AI. I completed a PhD with the Robotics Institute at Carnegie Mellon University, where I did research at the intersection of explainable AI and human-AI interaction. I was fortunate to be advised by Reid Simmons and Henny Admoni, as part of the Human and Robot Partners (HARP) Lab. I previously completed a Master's at Carnegie Mellon in robotics with Red Whittaker and Nathan Michael researching autonomous radiation source localization. Before that, I graduated from Princeton University ('16) with degrees in Mechanical & Aerospace Engineering and a certificate in Robotics & Intelligent Systems. My undergraduate thesis in computer vision on modeling uncertainty in feature-based visual odometry was advised by Nathan Michael and Jianxiong Xiao. |

|
|
|
|
Latest research. |
|
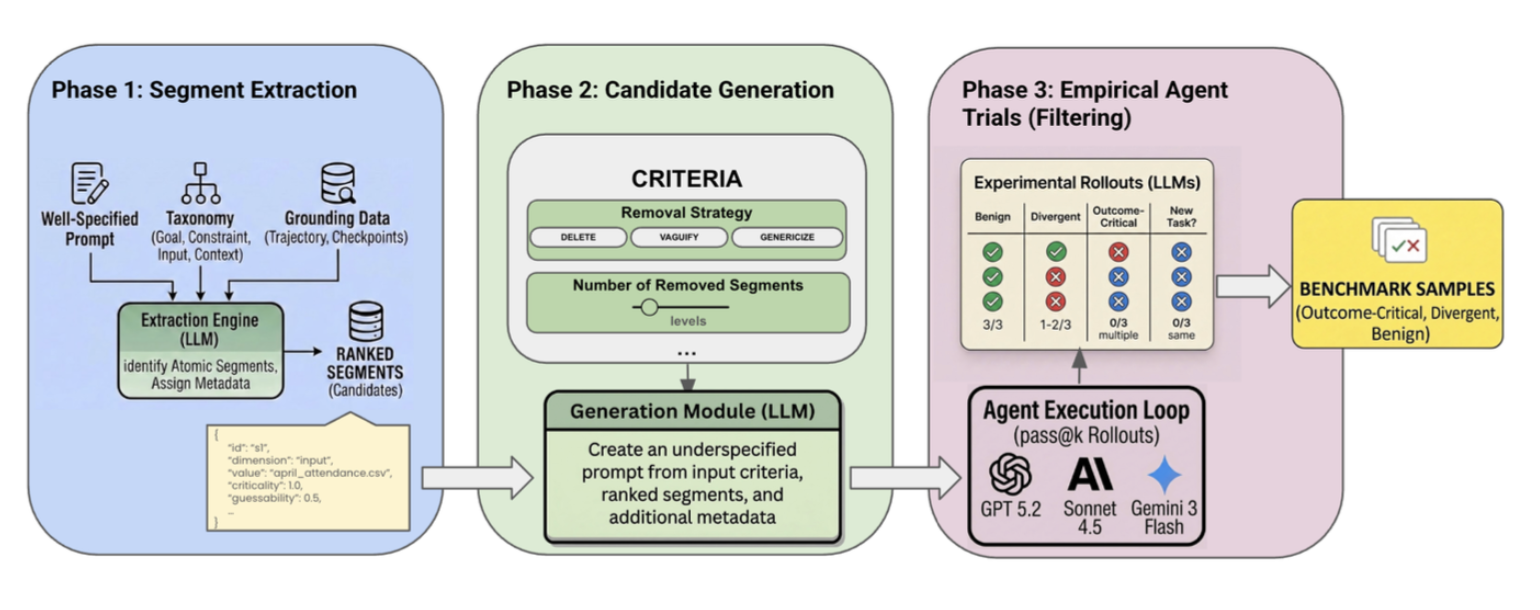
George Pu*, Michael S. Lee*, Udari Madhushani Sehwag, David J. Lee, Bryan Zhu, Yash Maurya, Mohit Raghavendra, Yuan Xue, Samuel Marc Denton Preprint, 2026 pdf / blog / dataset A dataset-agnostic pipeline for generating underspecified variants of long-horizon agent tasks and empirically validating the resulting ambiguity through agent execution. Applied to MCP-Atlas, TheAgentCompany, and SWE-Bench Pro, we release 285 benchmark-ready tasks that evaluate whether agents can strategically seek clarification when critical information is missing, and analyze the value, cost, and failure modes of clarification across frontier models. |

|
Yu Ying Chiu*, Michael S. Lee*, Rachel Calcott, Brandon Handoko, Paul de Font-Reaulx, Paula Rodriguez, Chen Bo Calvin Zhang, Ziwen Han, Udari Madhushani Sehwag, Yash Maurya, Christina Knight, Harry Lloyd, Florence Bacus, Mantas Mazeika, Bing Liu, Yejin Choi, Mitchell Gordon, Sydney Levine International Conference on Learning Representations (ICLR), 2026 pdf / website Evaluating the ability of models to reason through morally ambiguous scenarios, a testbed where multiple defensible conclusions exist (as opposed to math and code problems which often have objectively correct answers). We provide a dataset of 1,150 morally ambiguous scenarios, each paired with a set of rubric criteria that experts consider essential to include (or avoid) when reasoning; a subset is also analyzed under five major frameworks in normative ethics. |
|
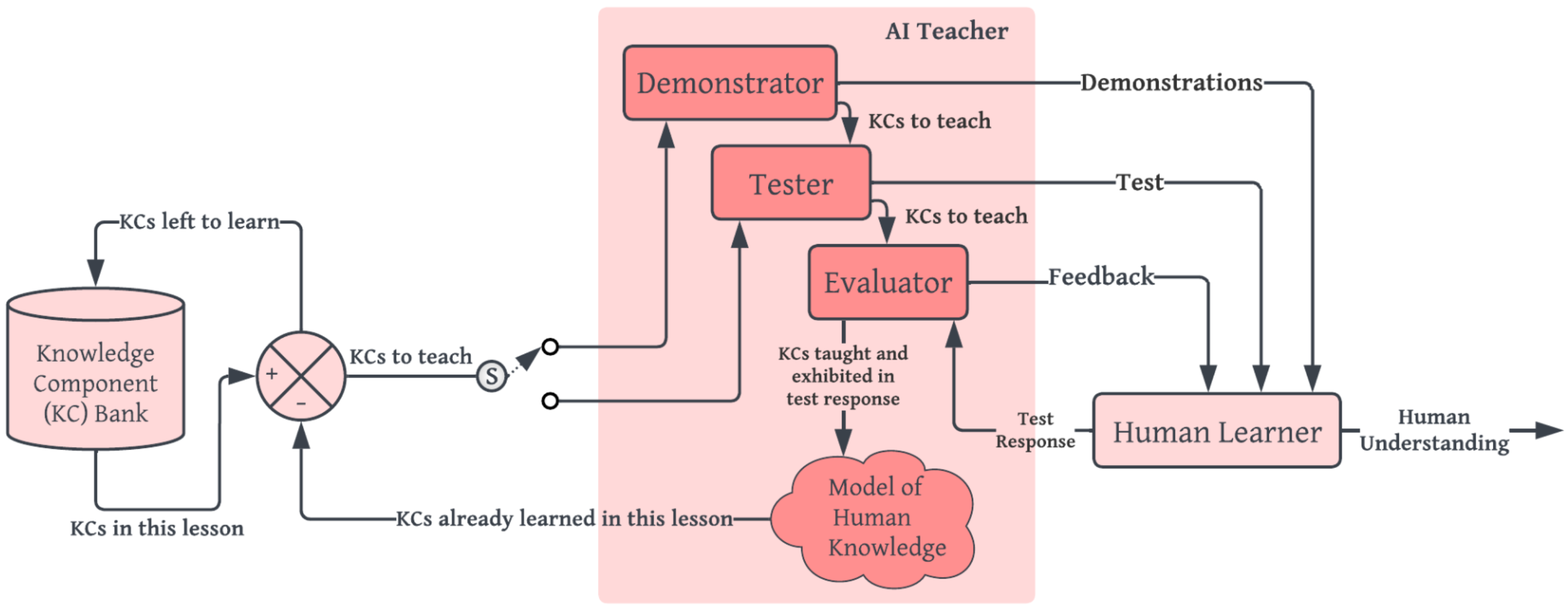
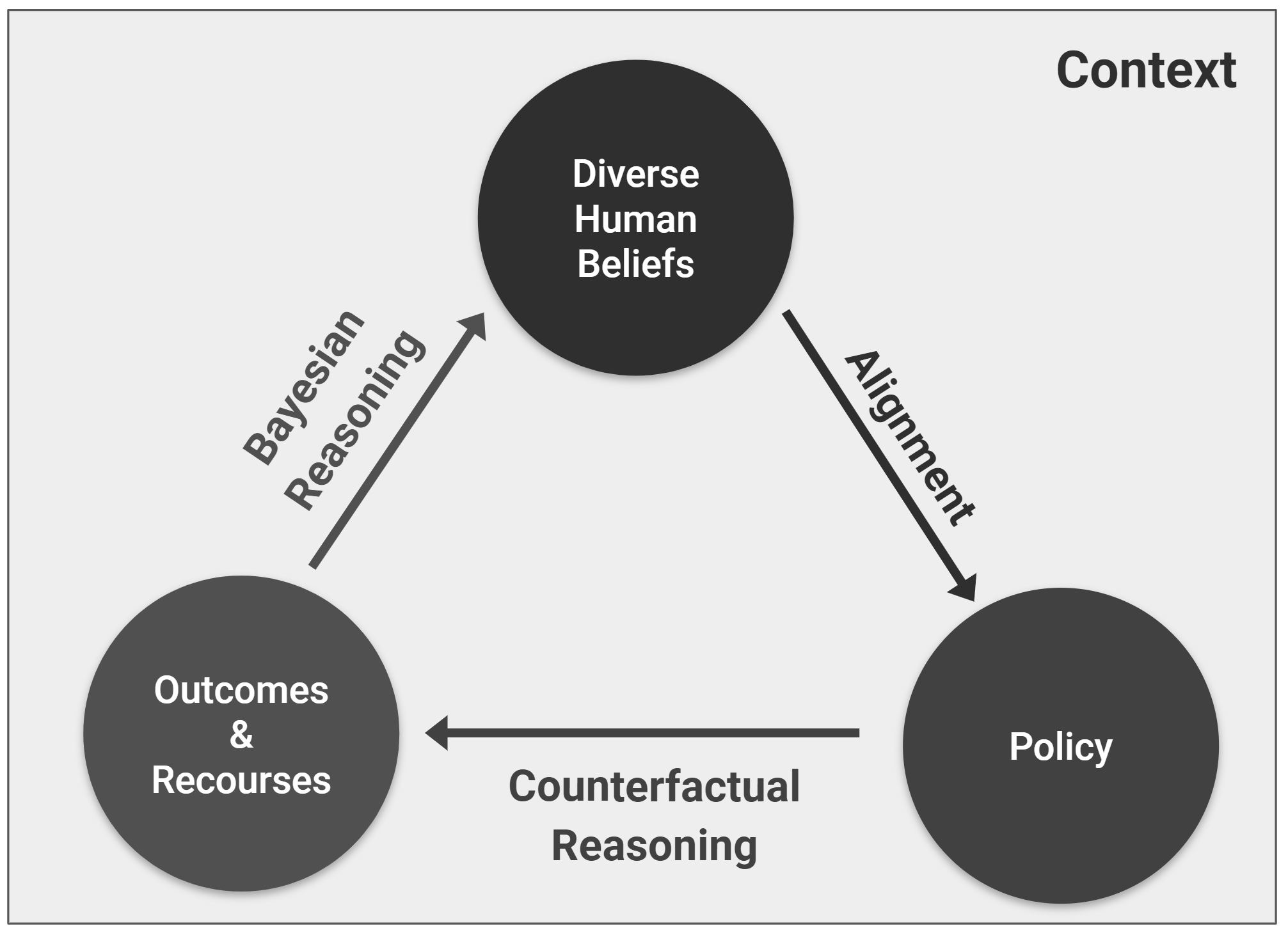
PhD research: Throughout my PhD, I published at top AI, machine learning, and robotics conferences (e.g. AAAI, IROS, HRI), workshops (e.g. ICML), and journals (Frontiers in Robotics and AI, THRI), and was selected into two doctoral consortiums (AAAI, HRI). I have been fortunate to collaborate with researchers at multiple institutions throughout my PhD (Google DeepMind, UMass Lowell, Tufts, BYU) which led to two joint publications. Toward greater transparency (i.e. understandability and predictability) of AI behaviors to humans, my research explored how an AI agent may teach its underlying reward function to a human learner using informative demonstrations that exhibit key tradeoffs in decision making. Our first key insight was that a demonstration's informativeness to a human is not intrinsic, but is inherently tied to that human's prior beliefs and their current expectations of agent behavior. We thus relied on inverse reinforcement learning and counterfactual reasoning (i.e. the extent to which the agent's demonstration deviates from the human's current expectations) to evaluate a candidate demonstration's informativeness to a human at revealing the agent's reward function. Our second key insight was that informativeness and difficulty of comprehension are often correlated, and we leveraged ideas from the education literature (e.g. zone of proximal development / "Goldilocks" principle) to ensure that the selected demonstrations presented the right level of challenge. If the difference between a demonstration and the human's expectation was too small, reconciliation would be trivial; if too large, the gap would be irreconcilable in one shot. We thus used scaffolding to provide demonstrations that incrementally increased in information gain and simultaneously eased humans into learning. Finally, we explored how to select a suite of informative tests that assessed the human's ability to predict agent behavior in unseen scenarios and revealed remaining gaps in the human learner's understanding, which were then bridged through subsequent targeted demonstrations in a closed-loop fashion. |
|
Michael S. Lee, Reid Simmons, Henny Admoni ACM Transactions on Human-Robot Interaction (THRI), 2025 pdf / code Designing a closed-loop teaching framework where AI policy is made more transparent to a human via demonstrations of AI behavior, tests, and feedback. A novel particle filter model of human beliefs is maintained to provide demonstrations that are targeted to the human's current understanding in real time. |
|
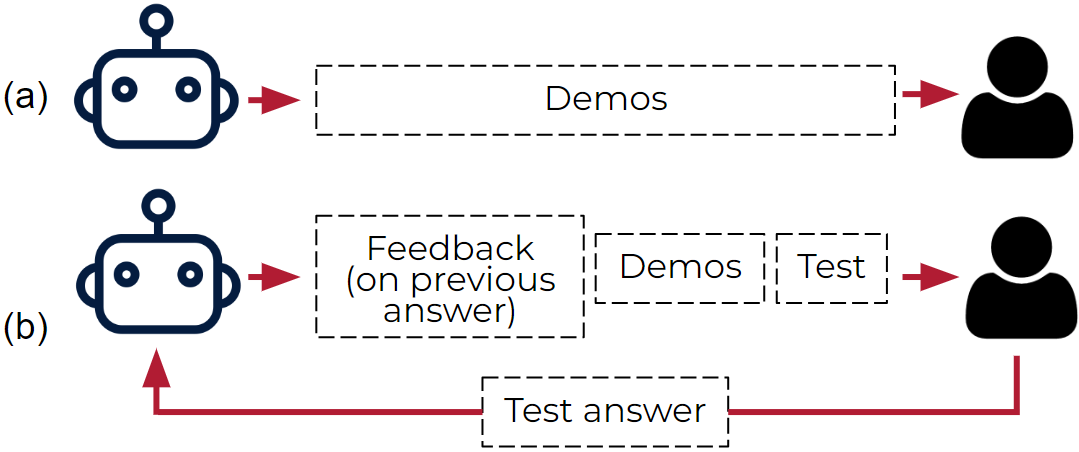
Michael S. Lee, PhD Thesis, 2024 pdf / code / slides Developing algorithms for teaching AI policies to humans using informative demonstrations of AI behavior. Conducted four user studies involving 750+ participants. Our teaching model reduces the suboptimality of human predictions of AI behavior by 64% over the baseline of directly providing the AI’s reward function. |
|
Michael S. Lee AAAI Doctoral Consortium, 2024 A 2-page research statement summarizing my dissertation research to date and highlighting potential directions for future work. |
|
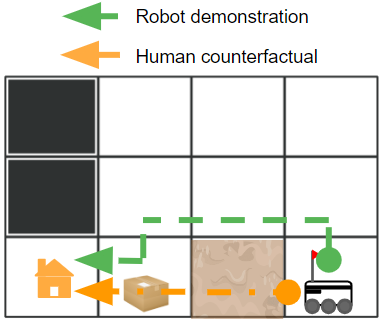
Michael S. Lee, Henny Admoni, Reid Simmons ICML Workshop on Counterfactuals in Minds and Machines, 2023 pdf / poster Reasoning over a human's counterfactual expectations of the AI's policy in real time to provide informative demonstrations of AI behavior that differ meaningfully. |
|
Qiuyi (Richard) Zhang, Michael S. Lee, Sherol Chen ICML Workshop on Counterfactuals in Minds and Machines, 2023 pdf / poster Leveraging counterfactual reasoning over possible outcomes and recourses to identify optimal belief strengths (i.e. parameters) for algorithmic decision making. |
|
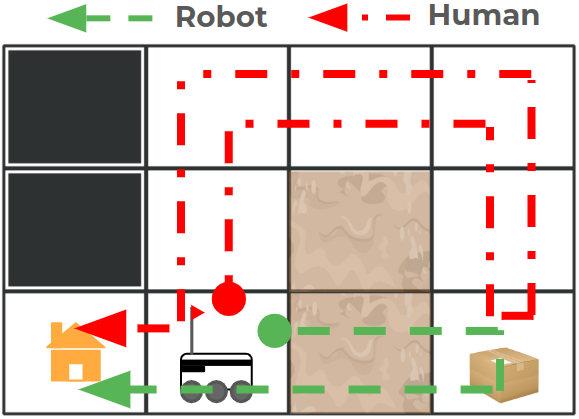
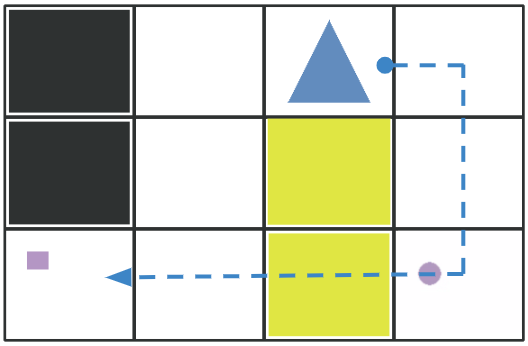
Michael S. Lee, Henny Admoni, Reid Simmons International Conference on Intelligent Robots and Systems (IROS), 2022 pdf / code / user study An informative demonstration is one that differs meaningfully from the learner’s expectations of what the robot will do given their current understanding of the robot’s decision making. |
|
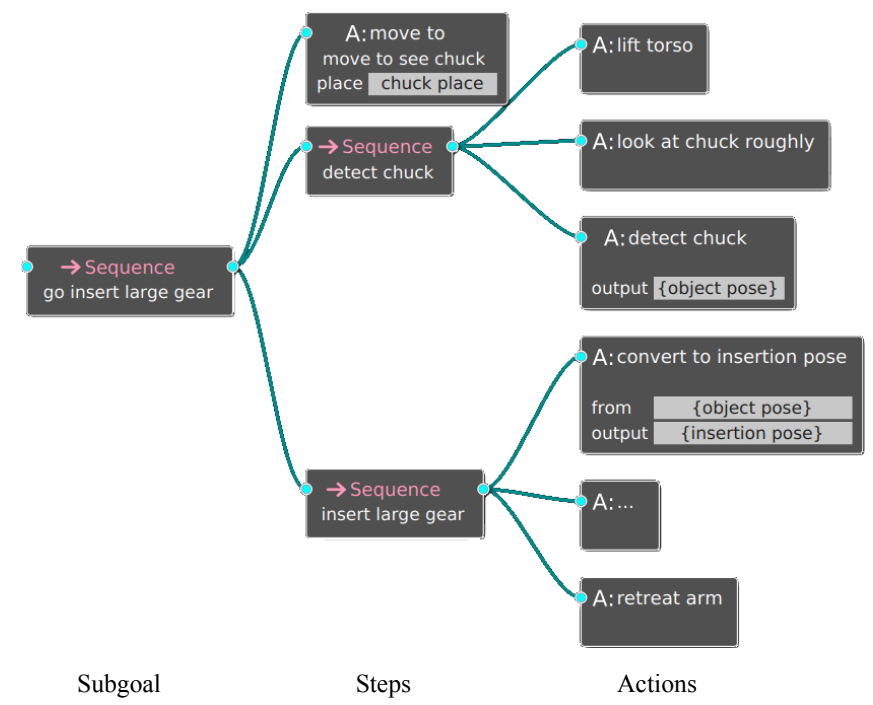
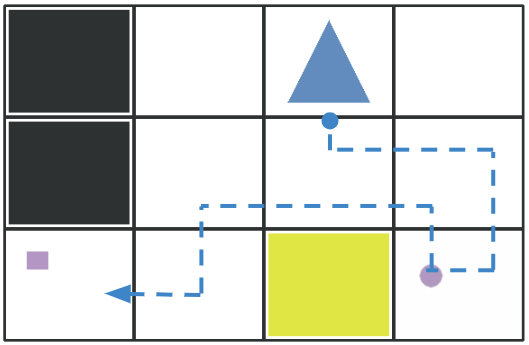
Zhao Han, Daniel Giger, Jordan Allspaw, Henny Admoni, Michael S. Lee, Holly Yanco ACM Transactions on Human-Robot Interaction (THRI), 2022 pdf / code / project page / slides A behavior tree hierarchically composed of goals, subgoals, steps, and actions supports explanation generation algorithms that convey causal information about robot behavior. |
|
Michael S. Lee, Henny Admoni, Reid Simmons Frontiers in Robotics and AI, 2021 pdf / code / user study Augmenting an inverse reinforcement learning model of how humans learn from demonstrations with teaching strategies (e.g. scaffolding, simplicity, pattern discovery, and testing) better accommodates human learners. |

|
Michael S. Lee, Pioneers Workshop at ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2019 A proposal for how a robot can actively assess both its proficiency at a task and its confidence in that assessment through appropriate measures of uncertainty that can be efficiently and effectively communicated to a human. |
|
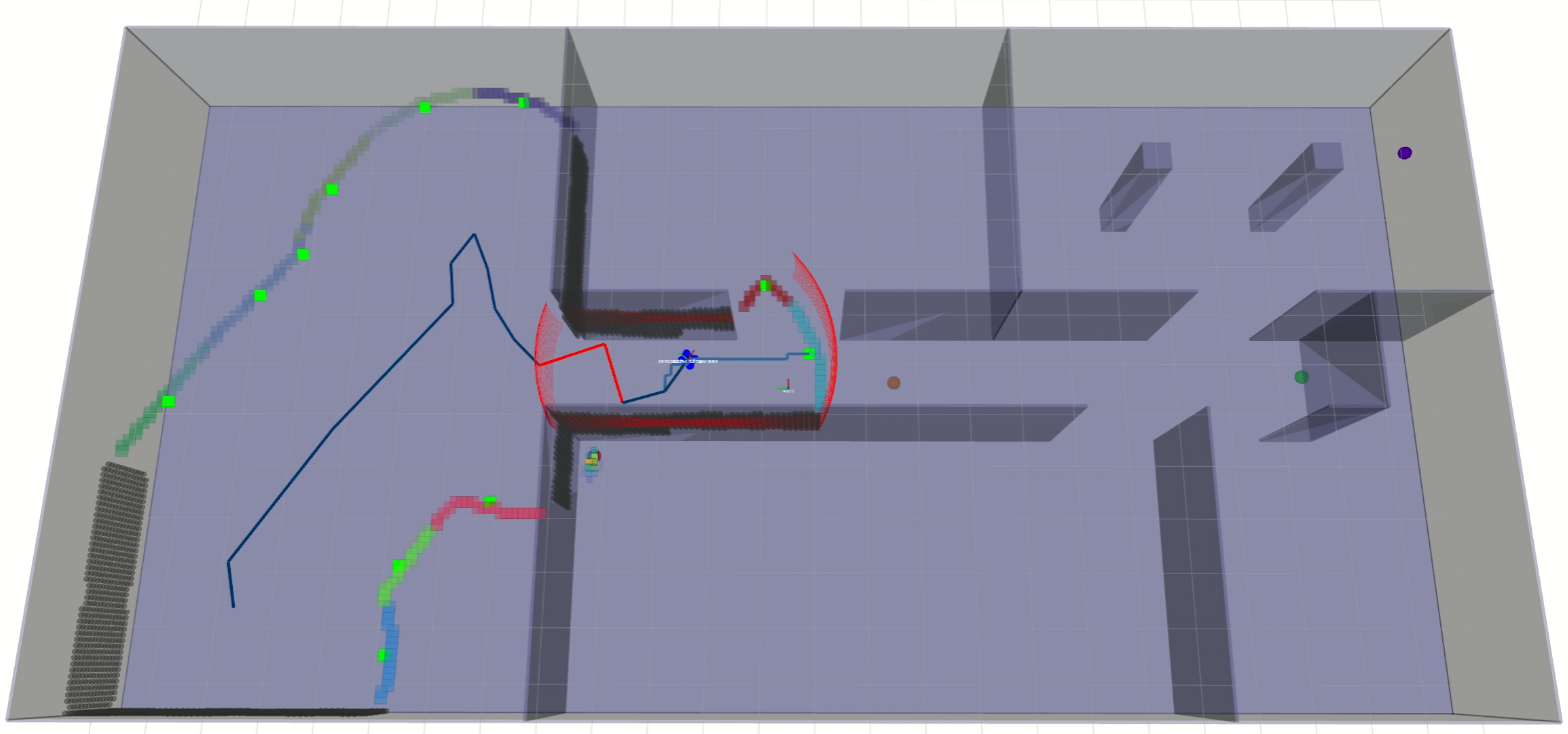
Master's Research: I previously developed a novel gamma radiation map representation, source localization algorithm, and frontier-based exploration for efficient radiological characterization of nuclear facilities using a robot equipped with a gamma-ray camera. |
|
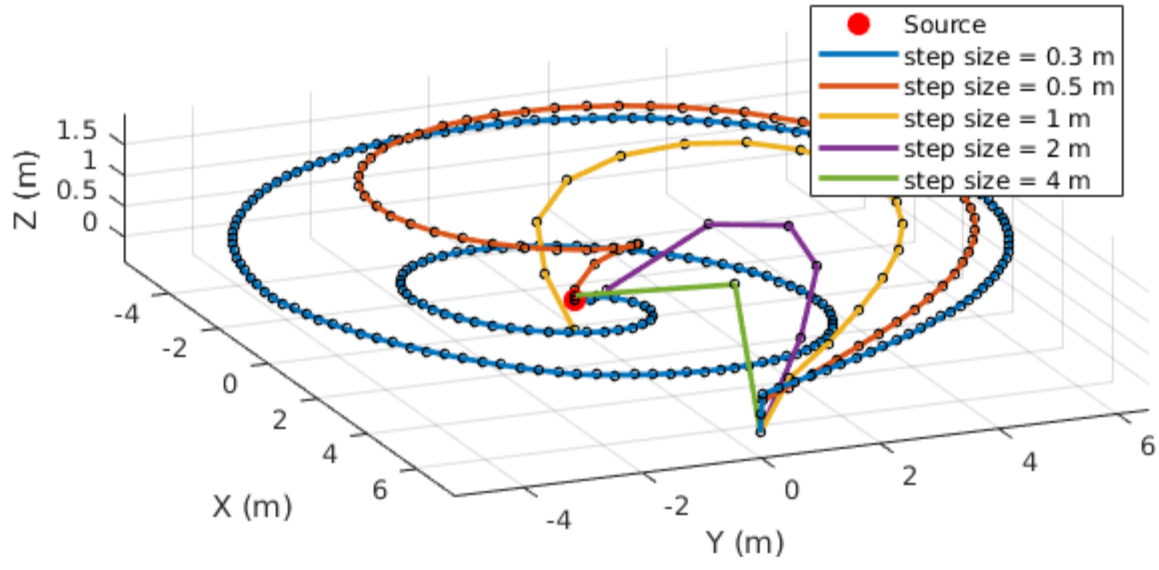
Michael S. Lee Master's Thesis, 2018 pdf / slides The proposed frontier-based exploration method biases frontier selection with the observed radiation field gradient to quickly search an environment until a proximal source is detected. |
|
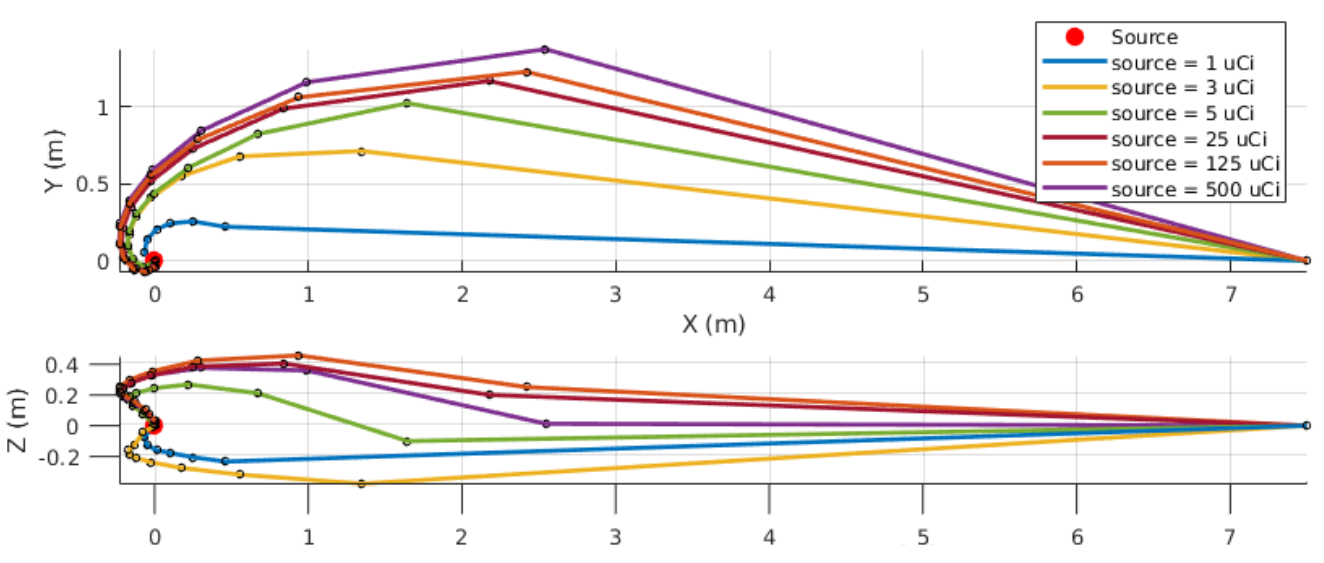
Michael S. Lee, Daniel Shy, Red Whittaker, Nathan Michael International Conference on Intelligent Robots and Systems (IROS), 2018 pdf / slides The proposed active source localization algorithm greedily selects new waypoints that maximize the Fisher Information provided by the gamma-ray camera’s range and bearing observations. |
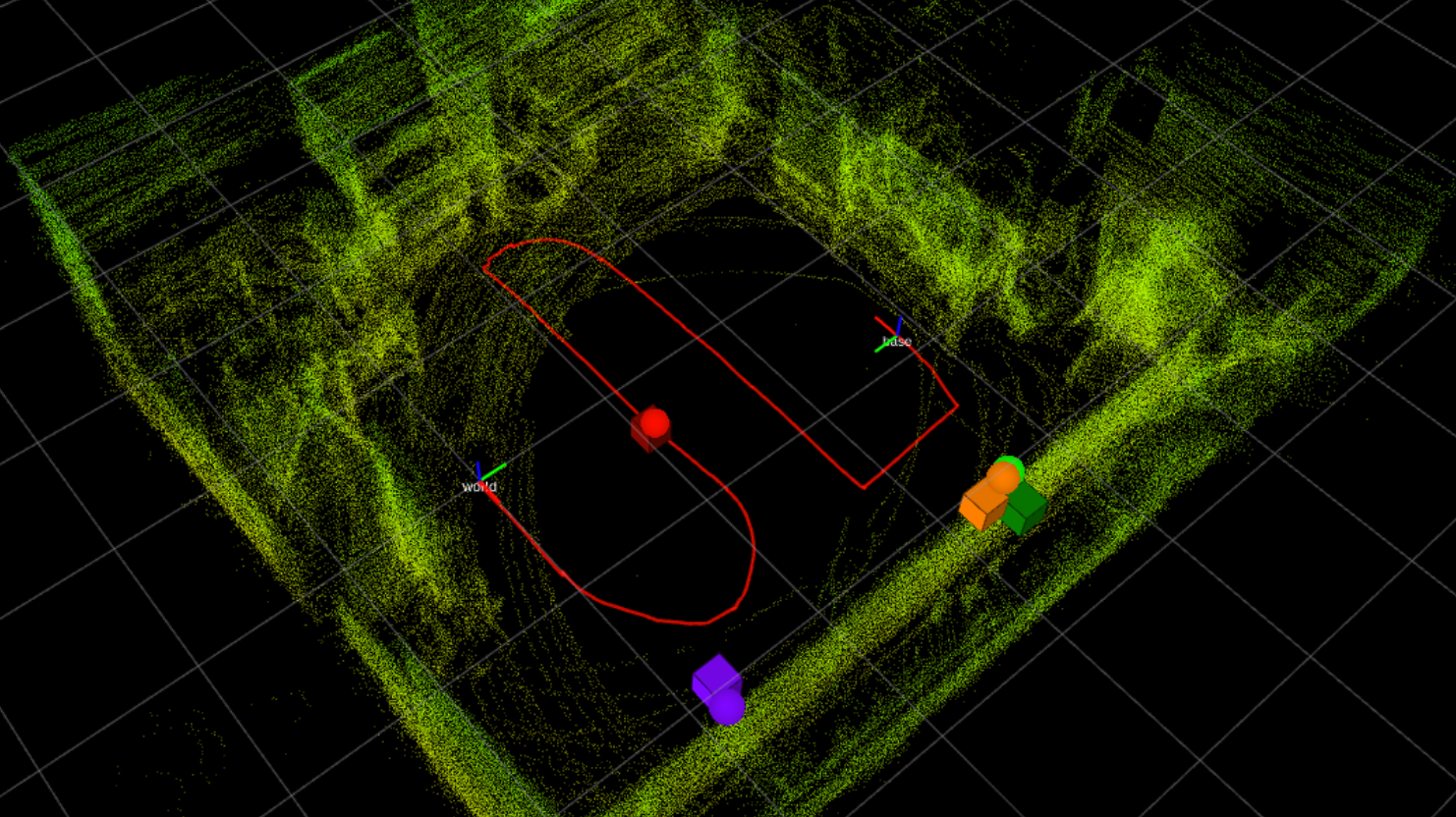
|
Michael S. Lee Matthew Hanczor, Jiyang Chu, Zhong He, Nathan Michael, Red Whittaker Waste Management Conference, 2018 pdf / slides A ground robot equipped with a Compton gamma camera localizes multiple gamma radiation sources to within an average of 0.26 m or 0.6% of the environment dimensions in two 5×4 m2 and 14×6 m2 laboratory environments. |
|
|